Uma GPU é basicamente um co-processador. Descarrega grande parte das cargas de trabalho redundantes que devem ser feitas com um elevado grau de simultaneidade para obter taxas de fotogramas adequadas nos gráficos 3D modernos.
O conceito de um co-processador pode ser familiar para aqueles que utilizaram um 80386. Havia um segundo chip chamado 80387 que se podia adicionar ao CPU para aumentar consideravelmente as velocidades de cálculo matemático.

O co-processador matemático 80387 era opcional. O PC ainda funcionaria bem sem ele.
Um co-processador é um adjunto especializado que desempenha uma função designada que não se enquadra realmente nos parâmetros funcionais do processador principal. O PC IBM era basicamente um processador de texto com alguns truques extra na manga. Podia lidar com operações básicas de folha de cálculo como as encontradas no Lotus 123. Mas nada super-intensivo.
O 80387 podia ser adicionado a um PC IBM ou a um dos seus clones para clientes que estivessem a fazer tarefas que sobrecarregariam um 80386 normal. A sobrecarga matemática extra foi passada para o 80387, de modo que o 80386 podia fazer o seu trabalho de executar as tarefas do dia-a-dia do PC.
As verdadeiros “GPU” ou aceleradores 3D como eram então conhecidos eram basicamente um co-processador matemático reforçado capaz de operações paralelas e especializadas que tratavam de operações matriciais e de rastreio. A GPU nem sequer era existia por si até 1996. Claro que se conseguia obter aceleração 3D numa estação de trabalho SGI de 150.000 dólares. Mas quantas pessoas vivas hoje em dia tiveram sequer a oportunidade de estar no mesmo edifício que uma estação de trabalho SGI?
Bem, três tipos deixaram a Silicon Graphics e fundaram uma empresa em 1994 chamada 3Dfx. No final de 1995, entraram na produção em massa do lendário chip 3D da Voodoo Graphics. A primeira placa a apresentar o novo Voodoo foi o Righteous 3D da Orchid. Lembro-me disso porque comecei a comprar todas as outras edições do Computer Shopper em finais de 1995. Orchid, Matrox, e Diamond eram três grandes nomes em placas gráficas.
A premissa básica de uma GPU ou Acelerador 3D é recolher tarefas de processamento para múltiplos núcleos, algo que as CPU’s não tinham em 1996, e que não teriam durante cerca de mais dez anos. Os primeiros aceleradores 3D possuíam talvez dezasseis núcleos. Um trabalho de renderização podia ser cortado em dezasseis peças mais pequenas e operado em simultâneo. Hardware especializado misturado sem problemas com software GPU. O 3Dfx utilizava o seu Glide API, muito da mesma forma que a Nvidia utiliza actualmente o CUDA API. O OpenGL já existia, mas o Glide permitiu à 3Dfx desenvolver o seu próprio software API à medida que o hardware evoluía. Os programadores Doom e Quake foram rápidos a abraçar a API do Glide e aceleraram grandemente a sua adopção e adaptação.
Já disse isto antes, mas sempre que configuro um PC com um CPU que nunca utilizei antes, corro sempre alguns parâmetros de referência antes de configurar os drivers integrados da GPU. Executar Unigine Heaven e Unigine Valley a 800×600 só na potência do CPU. O último CPU que configurei geriu 2,4fps com as configurações mais baixas absolutas. Uma vez instalados os drivers gráficos Intel HD, o mesmo benchmark nas mesmas configurações será suficiente, digamos apenas 28fps.
A iGPU funcionará cerca de 12X mais rápido do que a execução da aplicação apenas no CPU. Não só é 12X mais rápido, como também utiliza cerca de metade da potência. A GPU é um co-processador gráfico construído de propósito, concebido para fazer exatamente uma coisa. Os modernos designs integrados de GPU usam 192 núcleos, até à Skylake, Kaby Lake, Coffee Lake, e Comet Lake. Lembro-me de ter ficado boquiaberto quando a GPU Vega 11 no Ryzen 3400G tinha uns impressionantes 704 núcleos de GPU.
Posso estar a sobrestimar o número de núcleos de GPU nessas primeiras placas, porque a fenomenal GeForce4 Ti 4200 que usei durante dez anos tinha apenas 4 shaders de pixel, 4 ROPs, 8 TMUs, e 2 shaders de vértice correndo a uns ridículos 250MHz. A mera existência da especialização é o que a tornou tão rápida como era. Mais vale dizer que só tem quatro unidades de execução. E no entanto, ofereceu taxas de quadros muito sólidas até 1600×1200.

Pode ver a GeForce4 Ti 4200 gerindo 41fps a 1600×1200 em Serious Sam. Joguei Superbike 2000 a 1600×1200, e foi absolutamente fenomenal. Tive também a Athlon XP (funcionando a 1466MHz)- e até tive até o meu velho e louco NEC a funcionar até 2048×1536 durante algum tempo. A qualidade não era melhor do que 1600×1200, e o desempenho era muito pior, de modo que um ou dois dias depois deixei de utilizar.
A magia de Superbike 2000 foi a sua utilização extremamente eficaz na textura nos revestimentos. É possível ver as marcações extensas na relva, as árvores, as barreiras de segurança, as bordas das pistas e os guarda-corpos de aço. O céu em si é um BMP gigante que se enrola à sua volta como um tubo.
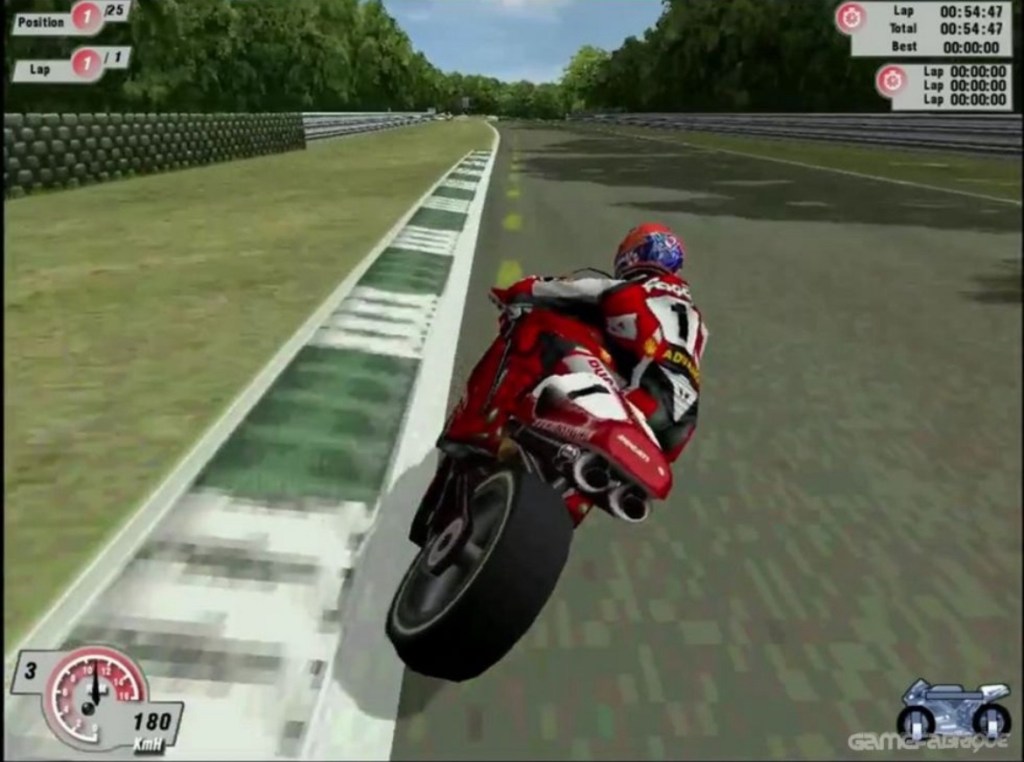
As mesmas duas dúzias de marcações de textura são usadas vezes sem conta, milhares de vezes, para um efeito que é absolutamente espantoso. Aquelas velhas placas com 128MB de VRAM e quatro unidades de execução fizeram um trabalho fantástico de entregar a essência do motociclista a 180 milhas por hora numa linda Ducati, bloqueando os travões no último segundo e mergulhando naquelas chicanes antes de carregar no acelerador para o lançar para fora das esquinas no fio da navalha do desastre.
Acredito firmemente que não é preciso gastar 1.600 dólares numa placa gráfica para ter uma explosão num PC de jogo. No entanto, é genuinamente urgente ter uma GPU com o poder de executar 4K com fluidez a 60Hz sem um soluço. Basta continuar a adicionar núcleos de GPU para ter em conta a complexidade da imagem e o enorme volume de pixels. Para gerir os incríveis detalhes dos títulos AAA modernos, o RTX 3080 tem um espantoso 8704 núcleos CUDA dispostos em 68 unidades de execução.
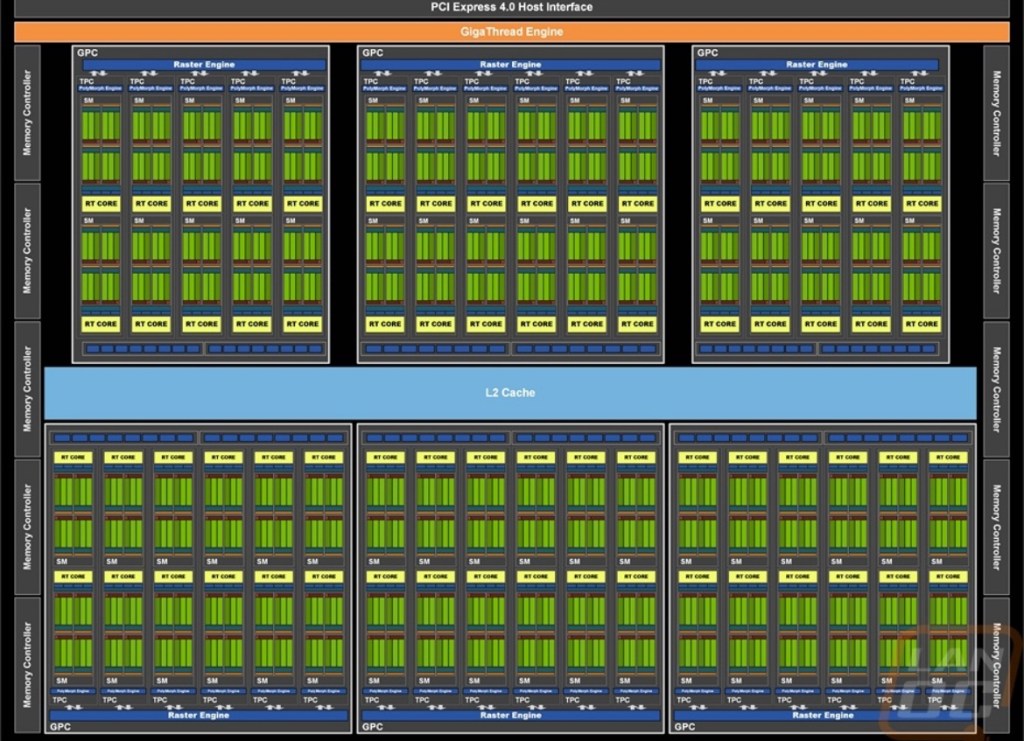
Se achar isso ultrajante, o RTX 4090 tem 76 mil milhões de transístores, consistindo em 16.384 núcleos CUDA em 128 unidades de execução. A minha antiga GeForce4 tinha 63 milhões de transístores. O RTX 4090 tem 76 BILHÕES/mil milhões!
Mas é possível ver o grau extremo de redundância. Cada unidade de execução ou multiprocessador de streaming é idêntico às outras. A quantidade de dados simultâneos que eles podem tratar é mais do que desconcertante. Um número simples como 87 TeraFLOPS é maior do que qualquer humano pode compreender.
A funcionalidade básica de um GTX 1050 não é muito diferente de um RTX 4090. O 4090 tem as capacidades adicionais dos núcleos RT juntamente com 25X o número de transístores e núcleos CUDA, utilizando apenas 6X a mesma quantidade de watts.
A GTX 1050, por sua vez, tem 50X tantos transístores como a GeForce4 Ti, enquanto funciona a 7X a velocidade do relógio.
Referência
Plataforma Quora, 2023. Acessado em 11 de outubro de 2023.
